Vygotskian Autotelic AI: Using Language as a Cognitive Tool
02 March 2021
In collaboration with Tristan Karch, Clément Moulin-Frier & Pierre-Yves Oudeyer. Reproduced from our team's blog .
Have you heard about DALL-E? Beyond the funny mashup between Pixar’s robot and the surrealist painter, Dall-E is OpenAI’s new transformer trained to compose images from text descriptions [DALL-E]. Most people agree, DALL-E’s ability to blend concepts into natural images is remarkable; it often composes just like you would. Look at these avocado-chairs:

Output from OpenAI’s Dall-E model when prompted by: "an armchair in the shape of an avocado” [Dall-E].
If it’s so impressive, it’s because this type of composition feels like a very special human ability. How would it know? The ability to compose ideas is indeed at the source of a whole bunch of uniquely-human capacities: it is key for abstract planning, efficient generalization, few-shot learning, imagination and creativity. If we ever were to design truly autonomous learning agents, they would certainly need to demonstrate such compositional imagination skills.
In this blog post, we argue that aligning language and the physical world helps transfer the structure of our compositional language to the messy, continuous physical world. As we will see, language is much more than a communication tool. Humans extensively use it as a cognitive tool, a cornerstone of their development. We’ll go over developmental psychology studies supporting this idea and will draw parallels with recent advances in machine learning. This will lead us to introduce language-augmented learning agents: a family of embodied learning agents that leverage language as a cognitive tool.
Language as a Cognitive Tool in Humans
Ask anyone what language is about. Chances are, they will answer something along these lines: “language is for people to communicate their thoughts to each other”. They’re right of course, but research in developmental psychology shows that language is a lot more. Vygotsky, a Soviet psychologist of the 1930s, pioneered the idea of the importance of language in the cognitive development of humans [Vygotsky, 1934]. This idea was then developed by a body of research ranging from developmental psychology, through linguistic to philosophy [Whorf, 1956; Rumelhart et al., 1986; Dennett, 1991; Berk, 1994, Clark, 1998, Carruthers, 2002 and Lupyan, 2012].

Lev Vygostky and his socio-cultural theory of cognitive development. Vygotsky is mainly known for two ideas. First, although language is initially learned through and for communication with others, it is later internalized and used as a cognitive tool to organize thoughts. As a consequence, important aspects of high-level cognitive functions have social origins. Second, caretakers often setup a Zone of Proximal Development to facilitate children learning. This can take the form of a scaffolding of the environment, demonstrations or linguistic aids adapted to the current level of the child---as the child progresses, caretakers propose new challenges just beyond their current capabilities.
Let us start with words. Words are invitations to form categories [Waxman and Markow, 1995]. Hearing the same word in a variety of contexts invites humans to compare situations, find similarities, differences and build symbolic representations of objects (dogs, cats, bottles) and their attributes (colors, shapes, materials). With words, the continuous world can be structured into mental entities, symbols which, when composed and manipulated enable reasoning and give rise to the incredible expressiveness and flexibility of human thoughts [Whitehead, 1927]. In the same way, relational language seems to offer invitations to compare and is thought to be the motor of analogical and abstract reasoning [Gentner and Hoyos, 2017].
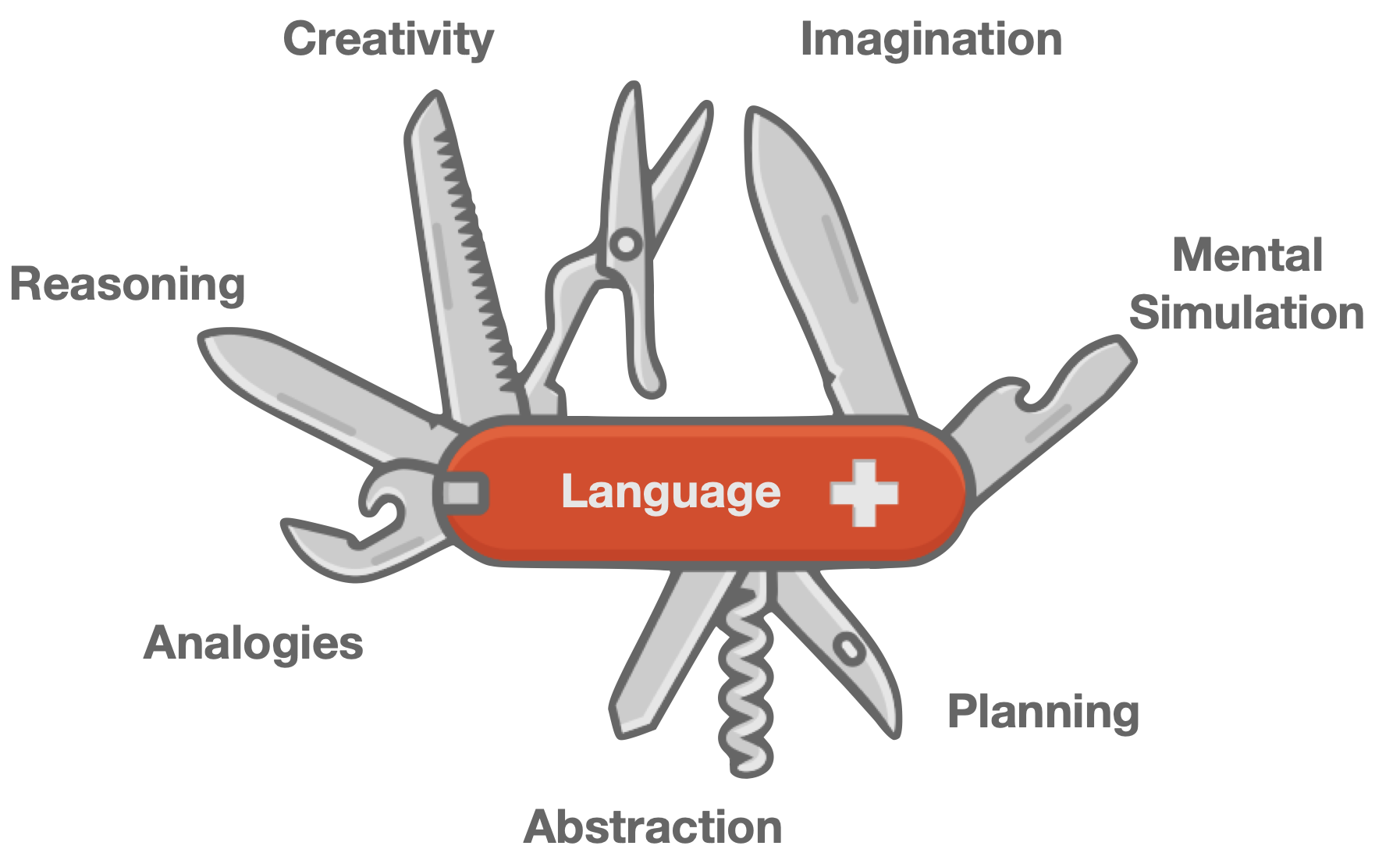
The Language Swiss Army Knife -- key cognitive functions enhanced by language.
More generally, the language we speak seems to strongly shape the way we think. [Lera Boroditsky’s Ted Talk] presents some examples of these effects. The perception of colors, for instance, is directly affected by the color-related words our language contains [Winawer et al., 2007] . Whether your language uses one word for each number or simply categorizes one, two and many will impact your ability to reason with numbers abstractly and thus to develop abilities for math and science [Frank et al., 2008] .
Vygotsky, Berk and others showed that private speech was instrumental to the ability of children to reason and solve tasks
Language can also be used as a tool to solve problems. Piaget first described that two-to-seven-year old children often use private speech or self-talk to describe their on-going activities and organize themselves, but thought this was a sign of cognitive immaturity [Piaget, 1923]. Vygotsky, Berk and others showed that private speech was instrumental to the ability of children to reason and solve tasks: the harder the task, the more intensively children used it for planning [Vygotsky, 1934, Berk, 1994]. Far from being left behind as children grow up, Vygotsky showed that private speech is internalized to become inner speech, the little voice in your head [Vygotsky, 1934 and Kohlberg et. al., 1968]. Children that cannot formulate sentences like “at the left of the blue wall” show decreased spatial orientation capacities in such contexts compared to children who can. Interfering with adults’ inner speech by asking them to repeat sentences also hinders their ability to orient spatially [Hermer-Vazquez et al. 2001].
Because language is—at least partially—compositional, we can immediately generalize and understand sentences that we never heard before. This is called systematic generalization: the ability to automatically transfer the meaning of a few thoughts into a myriad of other thoughts [Fodor and Pylyshyn, 1988]. Compositionality also underlies the reverse process: language productivity [Chomsky, 1957]. If words and ideas are like lego blocks, we can combine them recursively in infinite ways to form an infinite space of sentences and thoughts. This mechanism powers the imagination of new ideas and concepts that underlies many of the high-level cognitive abilities of humans. While our language productivity helps us generate new concepts like “an elephant skiing on a lava flow”, systematic generalization lets us understand them.
Once we have composed a new idea via language, it seems we can effortlessly picture what it would look like. Not convinced? Try to imagine what a cat-bus looks like and check here whether what you imagine matches Miyazaki’s creature. If most humans take this Dall-E-like ability for granted, studies showed that early contact with a compositional, recursive language is completely necessary. In neurobiology, this conscious, purposeful process of synthesizing novel mental images from two or more objects stored in memory is called Prefrontal synthesis (PFS) [Vyshedskiy, 2019]. Children born deaf with no access to recursive sign language and Romanian children left on their own in Ceausescu’s orphanages—among others—were shown to lack PFS abilities and failed to acquire abstract compositional thinking even after intensive language therapy [Vyshedskiy, 2019].
When PFS works, it seems to be easily triggered by language. The embodied simulation hypothesis indeed argues that humans have rich, multi-sensory representations prompted by language. If you read the sentence “he saw a pink elephant in the garden”, chances are you’re visualizing a pink elephant. More generally, understanding language seems to involve parts of the brain that would be active if you were in the situation described by the sentence. Reading about pink elephants? Your visual cortex lights up. Reading about someone cutting a tree? Your motor cortex lights up. This was even shown to work for metaphorical use of words [Bergen, 2012].
In a nutshell, humans use language as a tool for many of their high-level cognitive skills including abstraction, analogies, planning, expressiveness, imagination, creativity and mental simulation.
Language can only help if it is grounded in the physical world. Before drawing an avocado-chair, you need to know what avocados and chairs are; you need to know what drawing means. Our source of information comes from aligned data: as children, we observe and experience the physical world and hear corresponding linguistic descriptions. The mother could say: “This is a chair” when the infant is looking at it. The father could say: “Let’s put you on the chair” while the infant experiences being transported and sat on a chair.
Aligning language and physical data might just be about transferring the discrete structure of language onto the continuous, messy real world.
Language-World Alignment
As infants hear about chairs while experiencing chairs (seeing them, sitting on them, bumping their feet against it), they strengthen the association and build their knowledge of chairs.
It is now time to turn to artificial learning systems: AI systems also use aligned data! A basic example is the datasets of image and label pairs used by image classification algorithms. In language-conditioned reinforcement learning (LC-RL), engineers train learning agents to perform behaviors satisfying linguistic instructions: they reward agents when their state matches—is aligned—with the instruction. In real life however, children are not often provided with object-label pairs or explicit instructions. Caretakers mostly provide descriptive feedback, they describe events that are deemed novel or relevant for the child [Tomasello, 2005 and Bornstein et. al., 1992].
The IMAGINE agent receives such descriptive feedback [Colas et. al., 2020]. In Imagine, we look at how language can be used as a tool to imagine creative goals as a way to power an autonomous exploration of the environment—this will be discussed below. In a controlled Playground environment, the Imagine agent freely explores the environment and receives simple linguistic descriptions of interesting behaviors from a simulated caretaker. If the agent hears “you grasped a red rose”, it turns this description into a potential goal and will try to grasp red roses again. To do so, it needs to 1) understand what that means; 2) learn to replicate the interaction. The description it just received is an example of aligned data: a trajectory and a corresponding linguistic description. This data can be used to learn a reward function (1): a function that helps the agent recognize when the current state matches—is aligned—with the linguistic goal description. When the two match, the reward function generates a positive reward: the goal is reached. Given a few examples, the agent correctly recognizes when goals are achieved and can learn a policy to perform the required interaction via standard reinforcement learning using self-generated goals and rewards (2).

Example of a descriptive feedback used to ground language in an agent's behavior. The robot is initially targeting to grasp the yellow tennis ball but as it reaches another goal the social partner provides a description of it (image from [this post]).
Descriptive feedback is interesting because it facilitates hindsight learning. While instruction-based feedback is limited to tell the agent whether its original goal is achieved, descriptions can provide feedback on any interaction, including ones the agent did not know existed. As a result, information collected while aiming at a particular goal can be reused to learn about others, a phenomenon known as hindsight learning [HER]. In existing implementations of LC-RL agents, state descriptions can be generated by scanning possible descriptions with a learned reward function [IMAGINE], by a hard-coded module [ACTRCE and Jiang et. al., 2019] or by a learned captioning module trained on instruction-based feedback [HIGhER; Zhou et al., 2020 and ILIAD]. Given the same aligned data, one can indeed learn a reverse mapping, from the physical world to the language space. This captioning system can be used as private or inner speech to label new chunks of the physical world and generate more aligned data autonomously.
From Language Structure to World Structure
In the physical world, everything is continuous. Perceptual inputs are just a flow of images, sounds, odors; behavior is a flow of motor commands and proprioceptive feedback. It is very hard to segment this flow into meaningful bits for abstractions, generalization, composition and creation. Language on the other hand is discrete. Words are bits that can easily be swapped and composed into novel constructions. Aligning language and physical data might just be about transferring the discrete structure of language onto the continuous, messy real world.
Dall-E seems to be a very good example of this. Everything starts with aligned data—pairs of images and compositional descriptions—and that’s all there is. Dall-E is not creative per se, but descriptions and images—both constructed by humans—are indeed. Dall-E simply—but impressively—learns to project the structure of language onto the image space, so that, when a human inputs a new creative description, Dall-E can project it onto images. As we argued before, language facilitates some forms of creativity via simple mechanisms to compose concepts, form analogies and abstractions. Swapping words, composing new sentences, generating metaphors are all easier in language space than in image space directly.
Language-Augmented Reinforcement Learning Agents
Readers should now be convinced that autonomous embodied learning agents should be language-augmented; they should leverage language as a cognitive tool to structure their sensorimotor experience, to compose, generalize, plan, etc. Let us go over some first steps in that direction.
LC-RL methods often investigate the ability of their agent in terms of systematic generalization: the ability to interpret never-seen-before sentences by leveraging knowledge about their constituents. These sentences are known constructions with new associations.
Let’s consider an agent that learned to grasp plants and to feed animals by bringing them food. As it learned these skills, the agent acquired representations of the concepts of animals, plants, food and grasping. Can these concepts be leveraged to understand a new combination such as “feed the plant”? Here again, agents use aligned data (e.g. instruction-state or description-state) and are tested on their ability to project the compositional aspect of language (“feed the animal” + “grasp the plant” → “feed the plant”) to the behavioral space. Although it is not perfectly systematic, this type of generalization often works quite well, especially in settings where agents are exposed to a wide distribution of objects/words and perceive the world through an egocentric point of view that helps them isolate individual objects [Hill et. al., 2019].
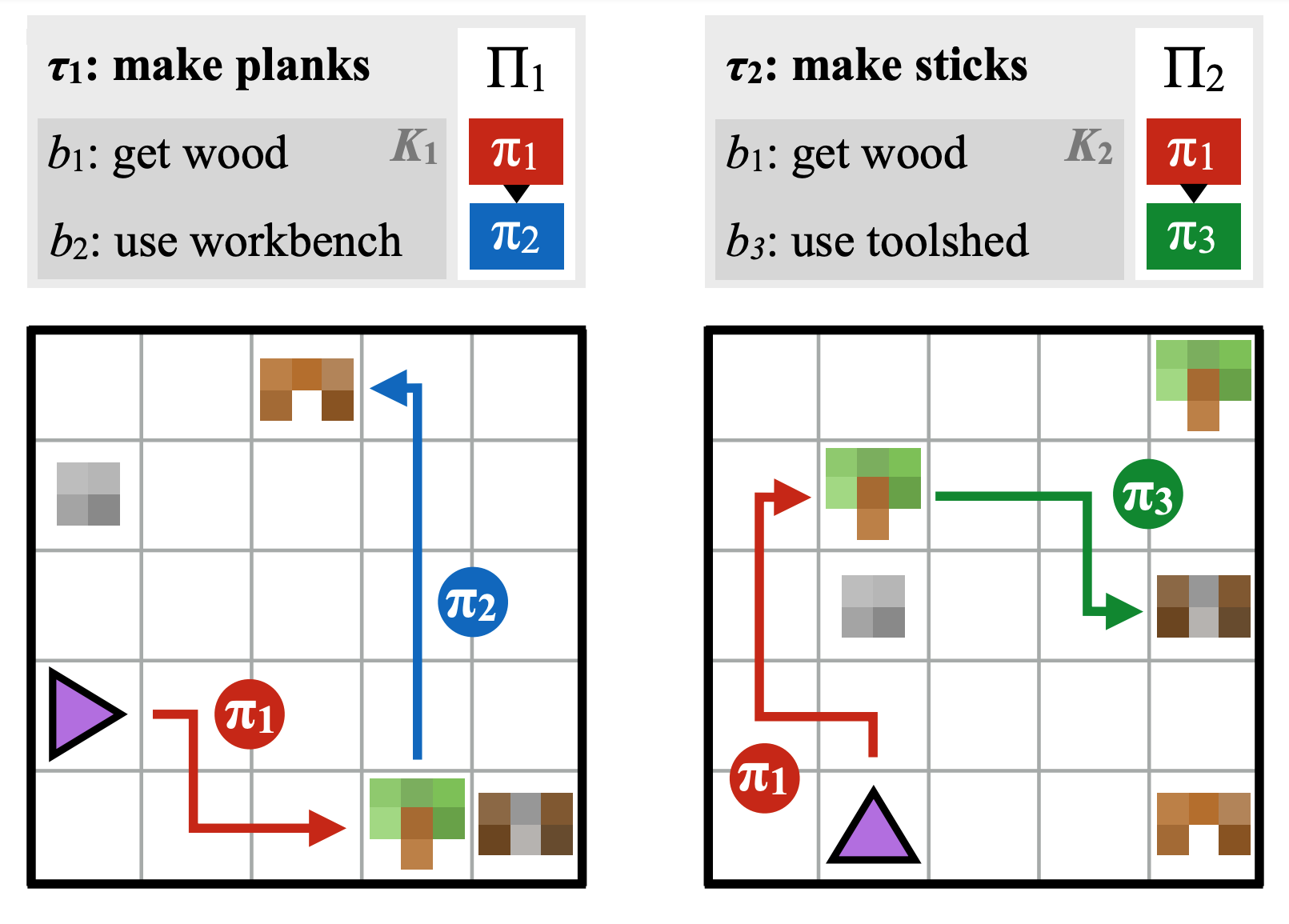
The Policy Sketches approach: long-horizon behaviors are aligned with policy sketches, sequences of symbolic tokens segmenting the long-horizon task into shorter steps [Policy Sketches].
Building on these generalization properties, language was also found to be a good way to represent abstractions in hierarchical reinforcement learning setups [Jiang et. al., 2019]. While the high-level policy acts in an abstract and human-interpretable representation space towards the resolution of long-horizon control problems, the low-level policy benefits from the generalization induced by language-behavior alignment. In Modular Multi-task RL with Policy Sketches, long-horizon behaviors are aligned with policy sketches, sequences of symbolic tokens segmenting the long-horizon task into shorter steps [Andreas et. al., 2017]. This simple alignment, along with a bias to encode each step-specific behavior with a different policy, is enough to significantly speed up learning without any explicit pre-training of the sub-policies. The sequential structure of the task into separate steps can be projected onto the behavioral space—i.e. sub-policies. Planning and reasoning in language space is much easier for humans and allows us to handle long-horizon tasks. Similarly, the Text-World approach defines artificial learning environments where agents observe and interact with text only [TextWorld]. This can be seen as a high-level world model in language space. Agents can efficiently explore and plan in the language space, then transfer this knowledge to an aligned sensorimotor space [AlfWorld].
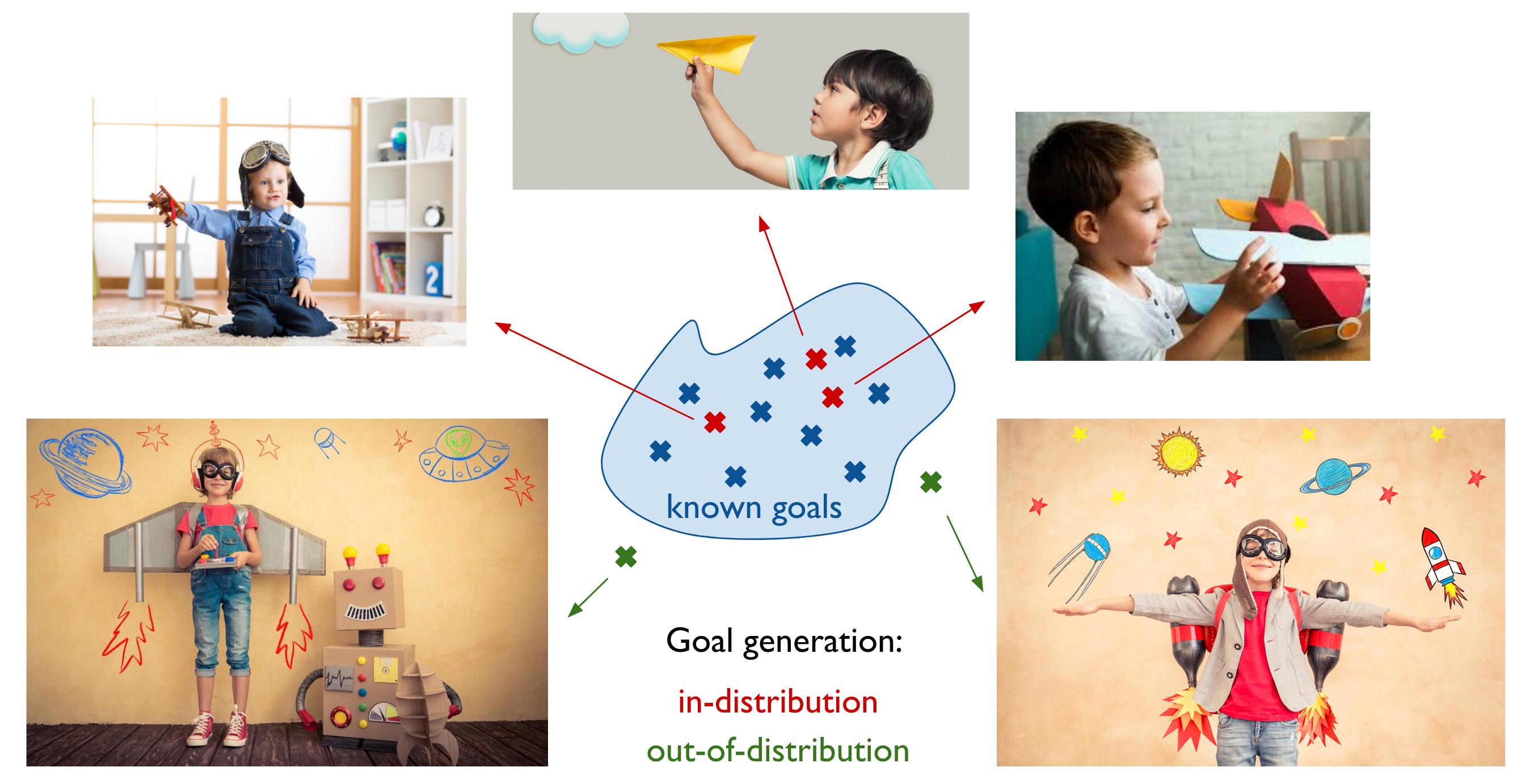
Out-of-distribution goal generation powers creative exploration.
Creative exploration is about finding new ways to interact with the environment. Agents can efficiently organize their exploration by generating and pursuing their own goals [Forestier et al., 2017].
Goal generation, however, is often limited to the generation of target representations that are within the distribution of previously-experienced representations. If we want to achieve creative exploration, we need agents to generate out-of-distribution goals, to imagine new possible interactions with their world. This is reminiscent of the way children generate their own creative goals during pretend play [Vygotsky, 1930], a type of behavior that is argued to benefit children’s ability to solve problems later on [Chu and Schulz, 2020].
If we want to achieve creative exploration, we need agents to generate out-of-distribution goals, to imagine new possible interactions with their world.
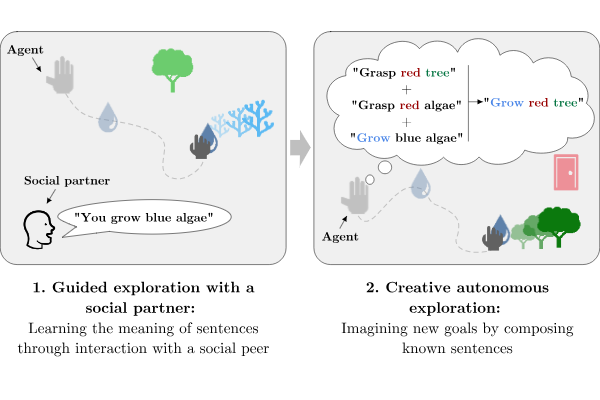
The Imagine architecture as a Vygostkian Deep RL system. Social interactions with a social peer enables the agent to learn to represent and understand language as a pre-existent social structure (left). Then, language is internalized and used as a cognitive tool to imagine novel goals by re-combining known sentences: the agent aims to achieve these goals autonomously, enabling creative free exploration (right). Another Vygostkian dimension of Imagine is that the social peer scaffolds the environment: when the agent imagines and formulates a goal through private speech, the social peer sets up the environment so that it's neither too hard (the right objects are present), nor too easy (procedurally-generated objects and additional distracting objects) [IMAGINE]. If you want to play with the code of IMAGINE, feel free to explore our Colab Notebook. The code base is also available in this github repo.
The IMAGINE agent we discussed above leverages the productivity of language to generate such creative, out-of-distribution goals—it composes known linguistic goals to form new ones, to imagine new possible interactions [IMAGINE]. The mechanism is crudely inspired by usage-based linguistic theories. It detects recurring linguistic patterns, labels words used in similar patterns equivalent and uses language productively by switching equivalent words in the discovered templates. This simple mechanism generates truly creative goals that are both novel and appropriate—see discussion in Runco and Jaeger, 2012. The novel and appropriate definition of creativity shares similarities with the intermediate novelty principle. Not novel enough is boring (known sentences), but too novel is overwhelming (sentences with random words). The sweet spot is in the middle—using novel instances of known constructions. We show that this simple mechanism boosts the agent’s exploration, as it interacts with more objects, driven by its imagined goals. Sometimes they make sense—the agent knows it can grasp plants and animals, and feed animals, so it will imagine it can feed plants as well. Sometimes they don’t and the agent might try to feed the lamp just like a child might feed his doll in pretend play [Vygotsky, 1933]. In any case, the agent is driven to interact with its world, with the objects around in a directed and committed way.
Goal imagination also boosts generalization for two reasons. First, imaginative agents train on a larger set of goals, thus extend the support of their training distribution and generalize better. Indeed, goal imagination enables agents to extend the set of known goals to a larger one made of all combinations of goals from the original set. Second, goal imagination can help correct for over-generalizations. In Playground, animals can be fed with food or water, but plants only receive water. When asked to feed plants for the first time (for evaluation purpose, i.e. zero-shot generalization), the agent over-generalizes and brings them water or food with equal probability—how could it know? When allowed to imagine goals, agents imagine that plants could be fed just like animals and try to do so—with water or food. Although the policy over-generalizes, the reward function can still identify whether plants have grown or haven’t. Agents detect that plants only grow when provided with water, never with food. As a result, the policy can be updated based on internally-generated rewards to correct for the prior over-generalization. Language does not need to correspond to a perfectly compositional world, the agent can correct for inconsistencies.
In another contribution, we introduce a language-conditioned goal generator to execute mental simulations of possible sensorimotor goals matching linguistic descriptions [LGB]. This Language-Goal-Behavior approach (LGB) decouples skill learning from language grounding. In the skill learning phase, LGB relies on an innate semantic representation that characterizes spatial relations between objects in the scene using predicates known to be used by pre-verbal infants [Mandler, 2012]. LGB explores its semantic space, discovers new configurations and learns to achieve them reliably. In the language grounding phase, LGB interacts with a descriptive caretaker that provides aligned data: linguistic descriptions describing LGB’s trajectories. This data is used to train the language-conditioned goal generator. When instructed with language, LGB can simulate/imagine several semantic configurations that could result from executing the language instruction. Instead of following the instruction directly as a standard LC-RL agent does, LGB samples a possible matching configuration and targets it directly. This type of mental visualization of the instructed goal is known to be performed by humans [Wood et. al., 1976] and allows agents to demonstrate a diversity of behaviors for a single instruction. This approach is reminiscent of the Dall-E algorithm and could integrate it to generate visual targets from linguistic instructions.
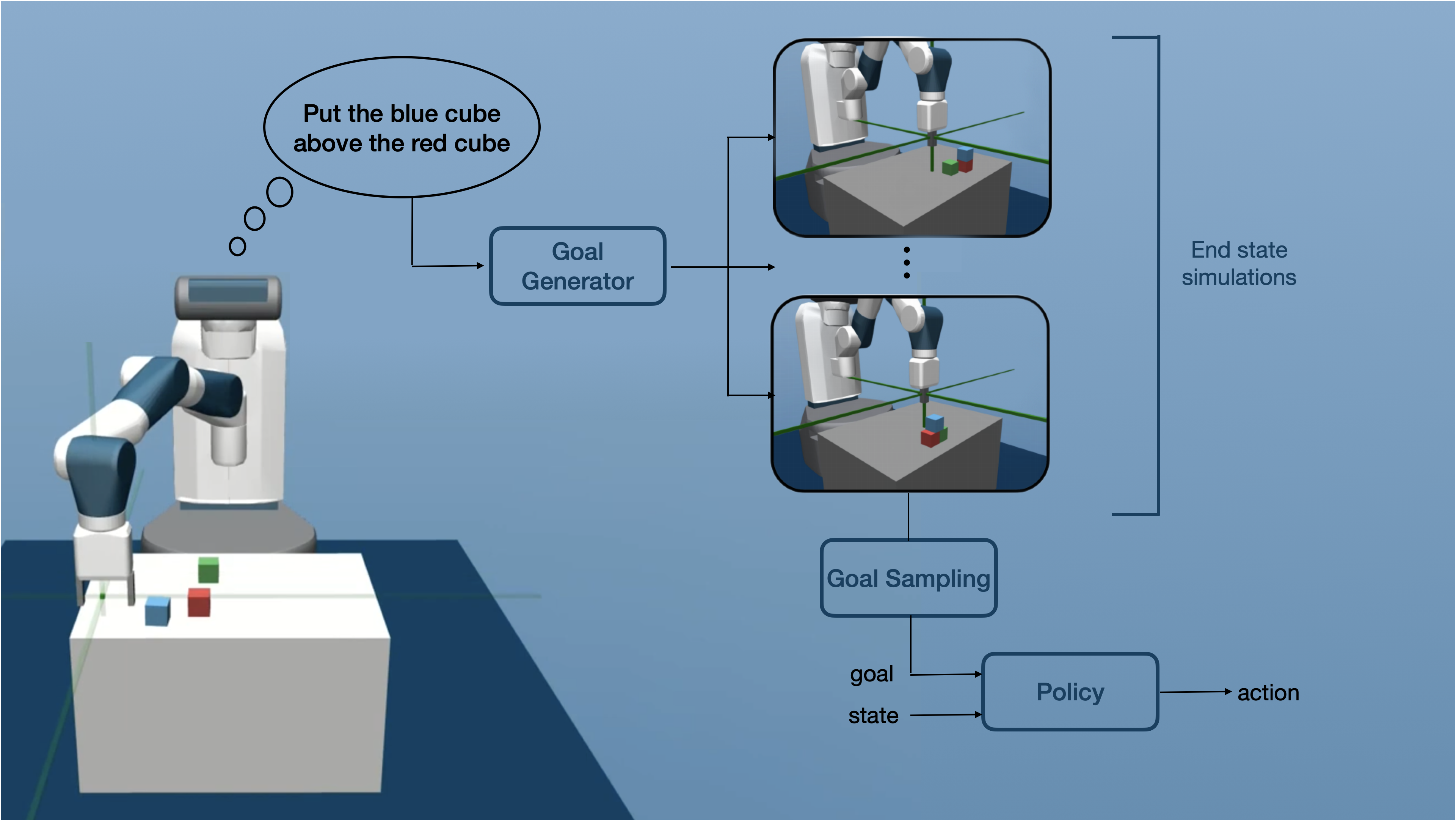
The Language-Goal-Behavior architecture [LGB]. The agent first generates a set of possible future configurations matching a linguistic description, then samples one of them as a concrete target.
The Big Picture
It is now time to take a step back. In this post, we’ve seen that language, more than a communication tool, is also a cognitive tool. Humans use it all the time, to represent abstract knowledge, plan, invent new ideas, etc. If it’s so helpful, it’s because we align it to the real world and, by doing so, project its structure and compositional properties to the continuous, messy physical world.
The embodied simulation hypothesis supports this idea. Humans seem to use language, to generate structured representations and simulations of what it refers to. This view is compatible with theories viewing humans as maintaining collections of world models [e.g. Forrester, 1971; Schmidhuber, 2010; Nortmann et al., 2013; Maus et. al., 2013 and Clark, 2015].
Now if we look at the algorithms discussed above under that lens, we’ll find that many of them are conducting mental simulations triggered by language. Dall-E certainly does; it generates visual simulation (i.e. visualizes) language inputs. That’s also what LGB does, it visualizes specific semantic representation that might result from executing an instruction. In a weaker sense, all LC-RL algorithms also do that: given a language input, they generate what’s the next action to take to execute the instruction. Model-based versions of these algorithms would do so in a stronger sense—picturing whole trajectories matching language descriptions. Finally, learned reward functions offer verification systems for mental simulation: checking whether descriptions and state—imagined or real—match.
These approaches are only the first steps towards a more ambitious goal—artificial agents that demonstrate a rich linguistic mental life. Just like humans, autonomous agents should be able to describe what’s going on in the world with a form of inner speech. The other way around, these agents should be able to leverage the productivity of language, generate new sentences and ideas from known ones and project these linguistic representations into visual, auditive and behavioral simulations. Linguistic productivity can also drive pretend play, the imagination of creative made-up goals for the agent to practice its problem resolution skills.
These approaches are only the first steps towards a more ambitious goal—artificial agents that demonstrate a rich linguistic mental life.
Only agents that conduct such an intensive alignment between language and the physical world can project linguistic structures onto their sensorimotor experience and learn to recognize the building blocks that will help them plan, compose, generalize and create.
This blog post covered works from developmental psychology and showed the importance of aligning language and physical experience in humans. Inspired by these studies, we argued for the importance of augmenting learning agents with language-based cognitive tools and reviewed first steps in that direction. Whereas standard language-conditioned RL approaches only use language to communicate instructions or state representations, language-augmented RL agents align language and sensorimotor interactions to build structured world models. Language-Augmented Reinforcement Learning (LARL) builds on the history of research in developmental psychology pioneered by the Russian school [Vygotsky, 1934] and the recent movement to transpose these ideas to cognitive robotics [Mirolli et al., 2011]. In LARL, language is used as the main cognitive tool to guide agents’ development. Artificial agents, just like humans, build language-structured world models that underlie high-level cognitive abilities such as planning, representation abstractions, analogies and creativity.
Acknowledgements
We would like to give a special thanks to Olivier Sigaud for his feedback and precious help on this blog.
Cite this blog post
@misc{colas:hal-03159786,
TITLE = {Language as a Cognitive Tool: Dall-E, Humans and Vygotskian RL Agents},
AUTHOR = {Colas, C{\'e}dric and Karch, Tristan and Moulin-Frier, Cl{\'e}ment and Oudeyer, Pierre-Yves},
URL = {https://hal.archives-ouvertes.fr/hal-03159786},
NOTE = {This blog post presents a supra-communicative view of language and advocates for the use of language as a cognitive tool to organize the cognitive development of intrinsically motivated artificial agents. We go over studies revealing the cognitive functions of language in humans, cover similar uses of language in the design of artificial agents and advocate for the pursuit of Vygotskian embodied agents - artificial agents that leverage language as a cognitive tool to structure their continuous experience, form abstract representations, reason, imagine creative goals, plan towards them and simulate future possibilities.},
YEAR = {2021},
MONTH = Mar,
HAL_ID = {hal-03159786},
HAL_VERSION = {v1},
}
References
- L. S. Vygotsky - Thought and Language 1934
- B. Lee Whorf - Language, Thought, and Reality, 1956
- D. E. Rumelhart, P. Smolensky, J.L McClelland and G. E. Hinton - Schemata and Sequential Thought Processes in PDP Models, 1986
- D. C. Dennett - Consciousness Explained, 1991
- L. E. Berk - Why Children Talk to Themselves, 1994
- A. Clark - Magic Words How Language Augments Human Computation, 1998
- P. Carruthers - The cognitive functions of language, 2002
- G. Lupyan - What Do Words Do? Toward a Theory The cognitive functions of languageof Language-Augmented Thought, 2012
- S. R. Waxman and D. B. Markow - Words as Invitations to Form Categories: Evidence from 12- to 13-Month-Old Infants, 1995
- A. N. Whitehead - Symbolism Its Meaning And Effect, 1927
- D. Gentner and C. Hoyos - Analogy and Abstraction, 2017
- J. Winawer, N. Witthoft, M. C. Frank, L. Wu, A. R. Wade and L. Boroditsky - Russian blues reveal effects of language on color discrimination, 2007
- M. C. Frank, D. L. Everett, E. Fedorenko and E. Gibson - Number as a cognitive technology: Evidence from Pirahã language and cognition, 2008
- J. Piaget - The Language and Thought of the Child, 1923
- L. Kohlberg, J. Yaeger and E. Hjertholm - Private Speech: Four Studies and a Review of Theories, 1968
- L. Hermer - Language, space, and the development of cognitive flexibility in humans: The case of two spatial memory tasks, 2001
- J. A. Fodor and Z. W. Pylyshyn - Connectionism and Cognitive Architecture: A Critical Analysis, 1988
- N. Chomsky - Synatctic Structure, 1957
- A. Vysgedskiy - Language evolution to revolution: the leap from rich-vocabulary non-recursive communication system to recursive language 70,000 years ago was associated with acquisition of a novel component of imagination, called Prefrontal Synthesis, enabled by a mutation that slowed down the prefrontal cortex maturation simultaneously in two or more children – the Romulus and Remus hypothesis, 2019
- B. K. Bergen - Louder Than Words, 2012
- M. Tomasello - Constructing a Language, 2005
- M. H. Bornstein, C. S. Tamis-LeMonda, J. Tal, P. Ludemann, S. Toda, C. W. Rahn, M-G. Pêcheux, H. Azuma and D. Vardi- Maternal Responsiveness to Infants in Three Societies: The United States, France, and Japan, 1992
- C. Colas, T. Karch, N. Lair, J-M. Dussoux, C. Moulin-Frier, P. F. Dominey and P-Y. Oudeyer - Language as a Cognitive Tool to Imagine Goals in Curiosity-Driven Exploration, NeurIPS 2020
- M. Andrychowicz, F.Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, W. Zaremba - Hindsight Experience Replay, NeurIPS 2017
- H. Chan, Y. Wu, J. Kiros, S. Fidler, J. Ba - ACTRCE: Augmenting Experience via Teacher's Advice For Multi-Goal Reinforcement Learning, 2019
- Y. Jiang, S. Gu, K. Murphy, C. Finn - Language as an Abstraction for Hierarchical Deep Reinforcement Learning, NeurIPS 2019
- G. Cideron, M. Seurin, F. Strub and O. Pietquin - HIGhER : Improving instruction following with Hindsight Generation for Experience Replay, 2020
- L. Zhou and K. Small- Inverse Reinforcement Learning with Natural Language Goals, 2020
- K. Nguyen, D. Misr, R. Schapire, M. Dudík, and P. Shafto - Interactive Learning from Activity Description, 2021
- F. Hill, A. K. Lampinen, R. Schneider, S. Clark, M. Botvinick, J.L. McClelland and A. Santoro - Emergent Systematic Generalization in a Situated Agent, ICLR 2020
- J. Andreas, D. Klein and S. Levine - Modular Multitask Reinforcement Learning with Policy Sketches, ICML 2017
- M-A. Côté, A. Kádár, X. Yan, B. Kybartas, T. Barnes, E. Fines, J. Moor, M. Hausknecht, R. Yu Tao, L. El Asri, M. Adada, W. Tay and A. Trischler - TextWorld: A Learning Environment for Text-based Games, 2019
- M. Shridhar, X. Yuan, M-A. Côté, Y. Bisk, A. Trischler and M. Hausknecht- ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, 2020
- S. Forestier, R. Portelas, Y. Mollard, P-Y. Oudeyer - Intrinsically Motivated Goal Exploration Processes with Automatic Curriculum Learning, 2020
- L. S. Vygotsky - Play and its role in the mental development of the child, 1933
- J. Chu and L. E. Schulz- Play, Curiosity, and Cognition, 2020
- J. M. Mandler - On the Spatial Foundations of the Conceptual System and Its Enrichment, 2012
- M. Akakzia, C. Colas, P-Y. Oudeyer, M. Chetouani, O. Sigaud- Grounding Language to Autonomously Acquired Skills via Goal Generation, ICLR 2021
- D. Wood, J. S. Bruner and G. Ross - The Role of Tutoring in Problem Solving, 1976
- J. W. Forrester - Counterintuitive Behavior of Social Systems, 1971
- J. Schmidhuber - Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010), 2010
- N. Nortmann, S. Rekauzke, S. Onat, P. Königand D. Jancke - Primary Visual Cortex Represents the Difference Between Past and Present, 2013
- G. W. Maus, J. Fischer, D. Whitney - Motion-Dependent Representation of Space in Area MT+, 2013
- Clark - Surfing Uncertainty, 2015
- M. Mirolli and D. Parisi - Towards a Vygotskyan Cognitive Robotics: The Role of Language as a Cognitive Tool, 2011